



Scalability 101: Vertical, Horizontal Scaling and Beyond

We often think of scalability same as performance (like how fast or how much a system can handle). This is partly true, but not exactly. Performance usually looks at how well one machine (with several CPUs) works under a set load. Scalability, however, is about handling changing or unpredictable loads.
In real life, systems face high traffic during peak times and much less at other times. A good scalable system can adjust to this by adding or reducing resources as needed.
There are two types of scalability: Vertical Scalability and Horizontal Scalability.

Vertical scalability means making a single server more powerful by adding resources like CPU or RAM. This is easy to do at first, but after a point, it gets expensive, and once you've upgraded, it's hard to go back. It’s a good option for small-scale needs.
Horizontal scalability, on the other hand, involves adding more servers instead of upgrading a single one. This gives almost unlimited flexibility to increase or decrease capacity as needed. However, it has its own challenges.
Up to a certain extent, Vertical scalability makes sense after that horizontal scalability becomes necessary. So in this article, we will focus more on that.
The key principles of horizontal scalability are:
1. Decentralization: Each component or service should handle one type of task instead of everything.
2. Independence: Components and services should work independently as much as possible. Complete independence isn’t always achievable, but reducing shared resources is important, as too much sharing can slow things down. This is explained in more detail by Amdahl's Law and the Universal Scalability Law in the previous article.
To achieve good horizontal scalability, we need to focus on key areas: replication, asynchronous processing, caching and partitioning.
Of course, microservices take horizontal scalability to the next level because we can auto-scale based on the load each specific microservice receives instead of the whole application. I won’t cover microservices in detail in this article, as I assume you already have a general understanding. If you have any questions, feel free to ask in the comments and I’ll be happy to answer.
Replication

We copy or replicate parts of our system, like backend services, frontend components, databases and more based on the load and requirement. There are two main types of replication:
Stateful Replication:
Here, data is also replicated. While we try to avoid this due to complexity, sometimes it’s necessary—such as with databases.Stateless Replication:
In this type, only code (not data) is replicated. This is preferred, especially for backend services.
Stateful Replication
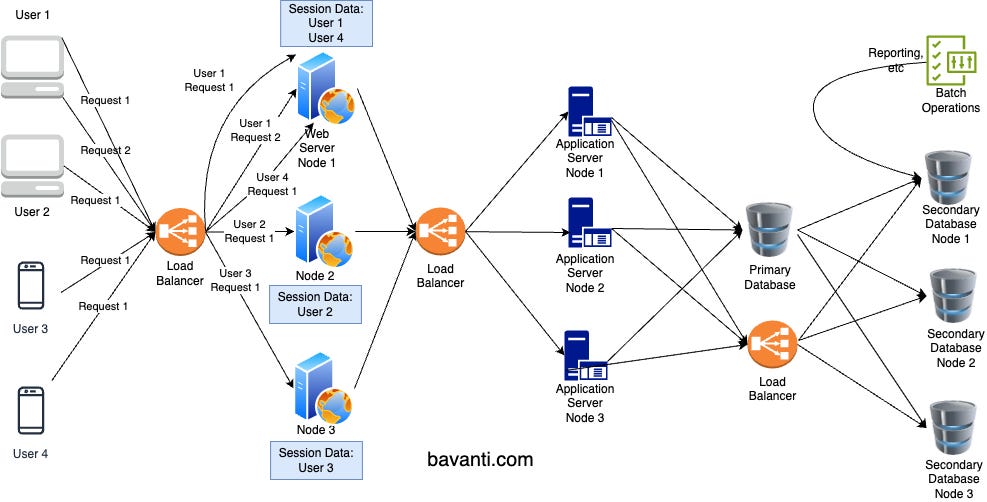
Stateful replication makes sense for databases or when building very low-latency applications. Otherwise, stateless replication is usually better.
For example, when we need user information (like roles), a web server typically requests it from the application server, which then fetches it from the database. To avoid these steps repeatedly, we can store this data temporarily at the web server level to speed things up. But this approach has some issues:
Scaling limitation due to Memory Constraints: Storing user data on the server uses up memory, limiting the number of users that can be handled.
Request Routing: If a user’s request goes to a different server, it might not have their data. There are two ways to address this:
Sticky Sessions: Ensures a user’s requests go to the same server by storing server details in a cookie or similar. You can see it in Figure 3, User 1 & User 4 session data is stored in Web server Node 1 because of that every request of those users go to Web Server Node 1 only.
Session Clustering: Shares session data across different servers so that any server can handle a user’s requests.
Reliability Issues: If the server storing session data goes down before saving it to the database, the session data is lost. To tackle it we can use techniques like Session Clustering.
Consistency Issues: If user data is updated in the database but not in the server’s memory, the server will have outdated (or stale) data.
Stateless Replication:
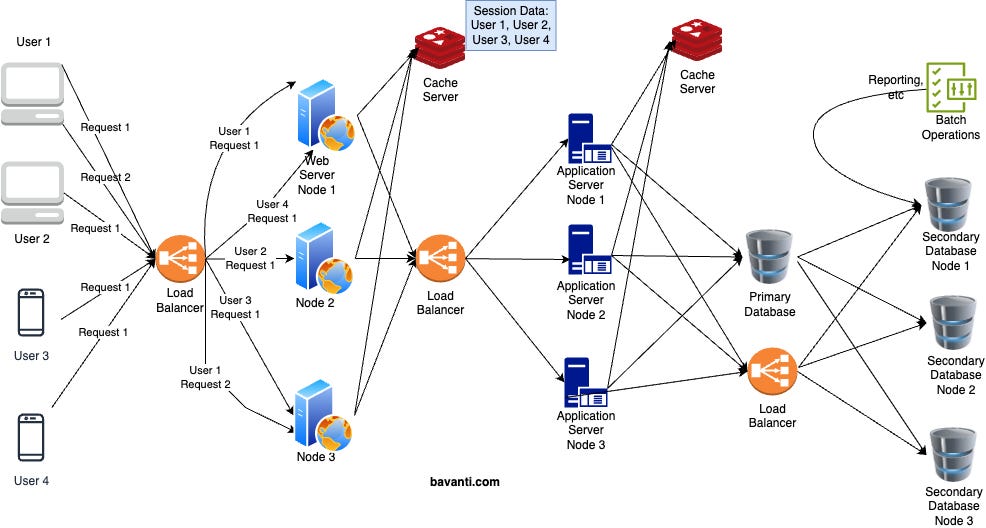
Mostly, it’s better to do Stateless Replication. However, this can lead to more interactions with the database, so to tackle that, we usually take these 2 approaches:
Keep Non-Sensitive Data on the Client Side: Store important but non-sensitive data at the user level, such as cookies or JWT tokens. This reduces the need for database calls, but be mindful not to store too much data, as it can increase data transfer costs and latency.
Add a Cache Server: Placing a cache server (like Redis or Memcached) between the application and the database can help reduce direct database interactions. While fetching data from cache is not as fast as accessing server memory, it’s still quicker than hitting the database and can significantly improve response times.
You can observe this in the Figure 4, request can go to any server for example user 1 request 1 went to Web server Node 1 and same user’s other request went to Web server Node 3 because they can pick the session data from the Cache server.
In this replication area, Database replication holds an important place so now let’s cover that. In this article I am going to cover only RDBMS(SQL) databases because if we touch No-SQL databases this article becomes very long, someday I will cover that too.
Datatabase Replication
Database replication is stateful, so it’s not easy to decrease capacity. There are 2 types of replications:
Primary-Secondary replication
In this setup, there is one main server (called the primary) that handles all write operations and several secondary servers (called replicas) that handle read operations only. You can read and write on the primary server, but you can only read on the replicas. There are also three types of replication in this setup.
Asynchronous replication: Replicas apply data changes asynchronously, so users may see outdated data for a short time. This type of replication is good for high throughput with stable latencies. The only downside in this setup is if the primary server goes down there will be a bit of data loss.
Synchronous replication: The primary server waits for acknowledgement from at least all replicas before committing a transaction. This type of replication provides high data consistency and no data loss but can impact performance a lot.
Semi-synchronous replication: Uses a mix of synchronous and asynchronous replicas. The primary server waits for acknowledgement from at least one replica before committing a transaction, then sends it to other replicas asynchronously. If you are looking for zero data loss and are ok with a bit of performance hit, this is the best strategy.
Peer-To-Peer replication
In peer-to-peer replication, every database server (or node) can write and update data to all other participating databases. This happens asynchronously, and it’s commonly used in NoSQL databases. This approach is great for read-and-write availability and scales.
However, there are some challenges, like writing conflicts and issues with data order and consistency. To handle this, a solid conflict-resolution strategy is needed. Peer-to-peer replication is often used in applications that operate across different regions. Writes occur on the local database server in each region, and over time, the data syncs across all other servers to ensure consistency.
Asynchronous Processing

Stateful replication is always tough to tackle especially if we come to the writing part of the database replication side we can scale up but not down and scale-up also won’t happen instantaneously. To tackle this kind of problem one of the best strategies is Asynchronous processing(Messaging queue).
Parts where we are ok to let the user acknowledge that we took the request and we can inform outcome later it’s better to deal with asynchronous programming. Mostly e-commerce or ticket booking systems(Figure 5) take our booking and then acknowledge that took the booking request and the booking's final status is updated later. Booking processing service pulls the booking request data from the messaging queue at its own speed, It needs to do many things like inventor check and update the inventory then store it in the database, inform the user that the booking is processed successfully and inform notification service to update the user.
In the above picture(Figure 5) a lot of things are there which represents whole application for now concentrate on Booking, Booking Queue & Booking Processor parts.
Messaging queue/Asynchronous programming works as a Battery on top of the Database layer at that time. Even If a sudden spike comes it will take it and put it in the Queue(Messaging queue) so that our service can pick things at its own pace so that when the load is less our system will catch up. By the way, Messaging queues are pretty good at auto-scaling.
Caching
Caching is another way to enhance the scalability of a system because we can store the data which is frequently read in a fast accessible space. This will speed up our system and also put less load on the Database & Services.
I covered this topic extensively in the previous article you can check it here.
Database Partitioning
When your system demands extreme scalability, database partitioning becomes essential. Initially, vertical partitioning can handle scaling to a certain extent. However, beyond a point, horizontal partitioning (sharding) is necessary.
One thing you need to remember database partitioning adds a lot of complexity and some of the things can’t be done easily or can’t be done at all like ACID transactions, join queries, etc.
Database Vertical partitioning with microservices

In vertical partitioning, data is divided into separate databases based on application modules or microservices. Each microservice has its own dedicated database.
For Example:
An
BookingDBfor the Booking service, which receives heavy traffic. This database can be scaled independently without affecting other services. You can observe this in Figure 6.Any data needed from another service is retrieved by calling the respective microservice.
Consider these points before taking this step:
Only use this approach for high-traffic microservices.
Introducing multiple databases adds complexity, so it’s better to keep everything in one database unless necessary.
Database Horizontal partitioning
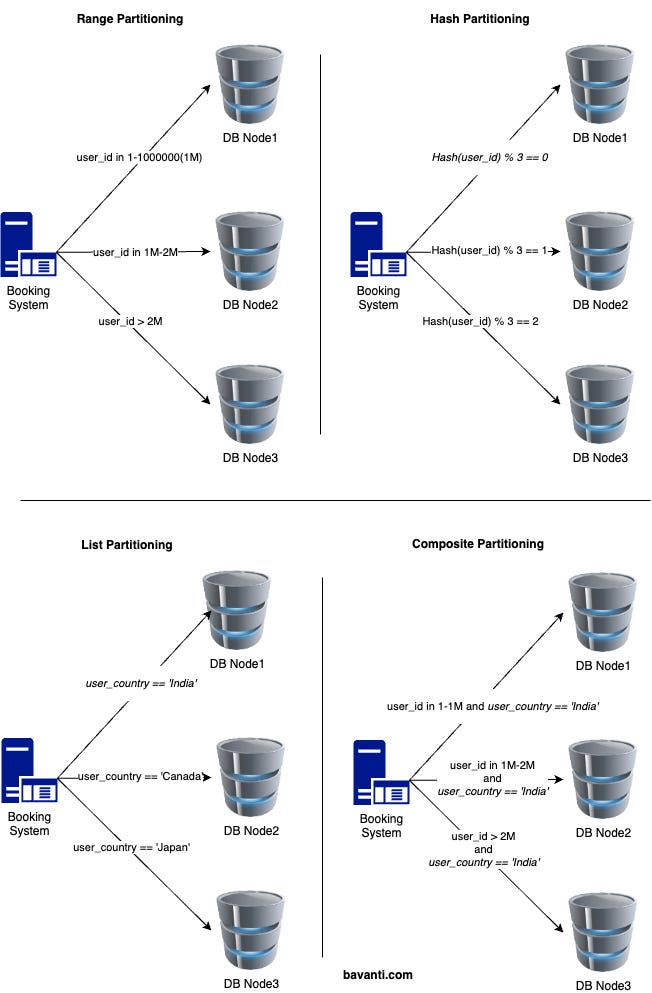
Horizontal partitioning divides data into smaller subsets (shards) based on rows. Each shard contains a portion of the data and is stored on a separate database instance.
There are popular Partitioning Strategies:
Range Partitioning
Data is divided into shards based on value ranges in a specific column.
Example: Booking Request by user id - 1-1,000,000(1M) in one shard, 1M-2M in another, etc.
Hash Partitioning
A hash function is applied to a column values, followed by a modulus operation to determine the shard.
Example: Hash(user_id) % Number_of_Servers determines the shard.
List Partitioning
Data is divided based on predefined lists of values.
Example: Booking Request data partitioned by country (e.g.,
India, Canada, etc).Composite Partitioning
Combines two or more strategies, such as range + hash or range + list.
Example: Booking Request partitioned by user_id (range) and country.
Key Considerations for Partitioning:
Avoid Hot Spots:
Ensure data is distributed based on usage patterns, not just data size.Example of a Hot Spot:
In a social media app, posts are distributed using a hash strategy. Even with even data distribution, a shard with celebrity accounts (e.g., Elon Musk, Justin Bieber) might receive disproportionate traffic, causing overload.
Choose the Right Strategy:
The partitioning strategy should align with your application's use case and traffic patterns.Plan for Migration Strategy:
When adding a new Database server to your application, data redistribution becomes necessary. For example, with a hash-based strategy, the hash values will change because the divisor (number of servers) increases from
nton+1. This means the data must be reshuffled across the servers.It's important to have a well-thought-out migration strategy to handle this process efficiently and minimize downtime or performance issues
Query Routing
The routing part needs to be taken care of because we need to know on which database node we need to run the query. These are some of the popular ways:
Client-Side Configuration: The client application is configured with mapping information to determine which shard to query directly. There are good libraries which support this.
Router Node: A dedicated router server acts as an intermediary between the client and the database shards. It routes queries to the appropriate shard based on pre-defined logic. Exp: MySQL Fabric, MongoDB Config Servers.
Metadata Server: A central metadata server maintains information about shard mappings and routing rules. Applications query this server to determine which shard to access.
Database-Native Sharding: Some databases natively support sharding and handle routing internally. The client interacts with the database as a whole or any node and the database manages query routing.
Did I miss anything? If yes, Please help me make it better by sharing your thoughts in the comments.
👋 Let’s be friends! Follow me on Twitter and connect with me on LinkedIn. Don’t forget to Subscribe as well.