



Concurrency and Parallelism: A Chef’s Guide to Building Scalable Systems

Before getting into Concurrency it’s always good to understand latency and improving it then coming to this area is advisable. If you want to know more about latency and how to improve read my previous article.

What is Concurrency?
Concurrency is the ability of a system to run multiple tasks or processes simultaneously or at overlapping times.
In the real world, you can say kind of preparing a curry. You start boiling water, then while the water is heating up, you chop vegetables. You're not doing both at the exact same moment, but you're switching between tasks in a way that both get done efficiently. That's how concurrency works in computing.
Asynchronous programming is a great testament to Concurrency. If we take Node.js as an example of asynchronous programming and concurrency, it handles tasks in an event-driven, non-blocking manner. This means that when Node.js takes on a task, it executes what it can immediately, especially if it's a CPU-bound task (like calculations or processing). But if the task involves waiting, like I/O operations (e.g., reading files, making network requests, or accessing a database), Node.js doesn’t just sit idle.
Instead of blocking the main thread while waiting for an external operation (like fetching data from a server or a database query), Node.js continues to work on other tasks. When the I/O operation is done, it "asynchronously" picks up where it left off, responding to the completion of the task via a callback or a promise.
This non-blocking behaviour shows how concurrency works in Node.js: even with only one thread, it efficiently manages multiple tasks by switching between them and handling what it can when the system is ready, all without waiting for one task to finish before starting another.
What is Parallelism?
Parallelism is doing multiple tasks or operations at the same time. It requires having multiple processors or CPU cores to do this.
If we take the above example. Think of it like a restaurant kitchen with multiple chefs. One chef is grilling the meat, another is making the salad and another is baking bread, all at the same time. Because they are working in parallel, the meal gets prepared faster than if a single chef tried to do all the tasks one after another.
MapReduce tasks are a great example of parallelism. If we take Spark as an example, it takes large data processing tasks and breaks them into smaller chunks, which can be processed independently and in parallel across multiple machines or processors. This enables fast and efficient processing of massive datasets.
Concurrency and parallelism are not the same but together they do wonders.
If we want to show it in a single picture I will say hands down to Alex Xu. Check this tweet. The below picture by Alex Xu sums everything up.

If you think Concurrency & Parallelism will solve all the performance problems in the world then you should be aware of these 2 laws.
Amdahl's law
Gunther's Universal Scalability Law
Amdahl's law
It is a formula that gives us an understanding that we will potentially speed up a task by parallelising some portions of that task but there are limitations. That speedup is limited by the sequential portion of the task that cannot be parallelized.
The law is expressed mathematically as follows:
p: The fraction of the task that can be parallelized.
n: The number of processors or cores used.
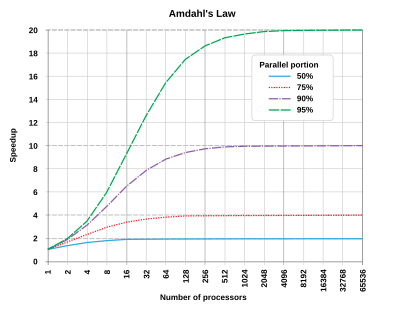
Amdahl's Law will tell you that no matter how much effort is put into parallelizing a process, the presence of any sequential portion limits the potential speedup. There is finally you will see the plateau based on the sequential portion of the overall task. The above picture will give you the idea.
Real World Example (Restaurant Kitchen)
Let’s take a restaurant kitchen as an example to understand Amdahl’s Law. Imagine you’re running a busy restaurant and need to prepare multiple dishes simultaneously. However, the kitchen doesn’t have an infinite number of ovens or stoves, so you are limited in how many tasks can be done in parallel.
Let’s say you have to prepare a large meal(Sunday Roast/Roast Chicken Dinner).
Sequential vs Parallel Parts:
Sequential Tasks:
Plating and Garnishing: This can only happen after all the other tasks are done, so it’s a sequential step that cannot be parallelized.
Parallel Tasks:
Roasting the Chicken, Boiling Vegetables and Making the Sauce: These can be done simultaneously, as long as you have enough stoves and ovens.
Breaking Down the Tasks:
Roasting Chicken: 40 minutes (in the oven).
Boiling Vegetables: 20 minutes (on the stove).
Making the Sauce: 15 minutes (on another stove).
Plating and Garnishing: 10 minutes (the sequential step after all cooking is done).
If you had unlimited ovens and stoves, you could parallelize most of the cooking, but you still can’t avoid the time for plating and garnishing, which is a sequential bottleneck.
Total Time (Sequential):
If you do everything sequentially, it will take:
Total Time = 40 + 20 + 15 + 10 = 85 minutes.
Total Time (with Parallelism):
If you can roast the chicken, boil the vegetables, and make the sauce at the same time, your total time will be:
Roasting Chicken: 40 minutes (this is the longest task).
Boiling Vegetables and Making the Sauce: These can be done in parallel to roasting chicken, so you don’t have to add their times.
Plating and Garnishing: 10 minutes (sequential step after cooking).
Total Time with Parallelism = 40 minutes (cooking) + 10 minutes (plating) = 50 minutes.
Amdahl's Law Application:
In this case, the speedup due to parallelism is limited by the sequential part, which is plating and garnishing. Even though you can cook multiple parts of the meal at the same time, the overall time is still constrained by the 10 minutes you need for plating and garnishing.
Let’s break it down using Amdahl's Law:
N (number of parallel tasks): 3 (Roasting Chicken, Boiling Vegetables and Making the Sauce).
This means that overall this task could be up to 2.143 times faster, highlighting that the serial portion limits the maximum achievable speedup.
Even if you had more stoves or ovens to parallelize the cooking, the speedup you can achieve is limited by the sequential part (like plating or roasting chicken which can’t be done by adding more ovens). This shows that the overall speedup isn’t infinite because there’s a limit to how much you can parallelize due to the sequential bottlenecks in the process.
Gunther’s Universal Scalability Law
I hope you got a good idea about Amdahl’s Law. If not please get it because Gunther’s Universal Scalability Law (USL) is an extension of Amdahl’s Law. While Amdahl’s Law focuses on the limits of parallelism in the presence of a sequential bottleneck, Gunther's USL incorporates additional factors, such as contention and coherency delays, to more accurately predict the real-world performance of systems as you scale the number of processes or resources.
Key Concepts in Gunther’s Universal Scalability Law:
Linear Scalability:
In an ideal scenario, if you double the resources (e.g., CPUs or servers), you would expect the performance to also double. This represents linear scalability.
Contention:
As you increase the number of resources (e.g., CPUs or servers), some resources may need to wait for access to shared resources (e.g., memory, storage, network bandwidth). This is called contention, and it causes the performance gains to diminish as more resources are added.
Coherency (or Coordination) Delay:
In distributed systems, the resources often need to coordinate with each other to maintain consistency (e.g., ensuring all servers have the same state in a database). This coordination adds an overhead known as coherency delay, which can actually cause performance to degrade as more resources are added, resulting in negative scalability beyond a certain point.
The formula for Gunther’s Universal Scalability Law is:
S(N) is the speedup or scalability of the system with N resources.
N is the number of resources (e.g., CPUs or servers).
α (alpha) represents the contention factor.
β (beta) represents the coherency or coordination delay factor.
Gunther’s law will tell us that:
At a small scale means at low values of N(which means doubling or tripling the number of processors), the system may scale well and achieve close to linear performance gains.
At a moderate Scale, As N increases, contention(α) begins to impact performance, causing the scalability to deviate from the ideal linear speedup.
At a Large Scale, As N grows even further, the coherency(𝛽) term becomes dominant, potentially causing negative scalability, where adding more resources actually degrades performance.

Real World Example (Restaurant Kitchen)
If we take the restaurant kitchen example again, adding a few Chefs and Stations, at first will see a clear performance boost.
As we keep on adding more chefs and adding stations, the gains in performance start to slow down because the kitchen will have limited shared resources, such as shared ovens, fryers, stoves and storage spaces because contention will creep in like they need to wait for accessing the oven or fryer to finish certain parts of their dishes.
Eventually, the kitchen becomes overcrowded with too many chefs working at the same time leading to Coherency issues(Chefs need to frequently check the status of shared resources (like the oven)) like who’s using the oven, who’s plating, etc. This leads to Negative scalability because dishes take longer to complete because of the extra coordination overhead.
I hope you understand that throwing a big machine(s) won’t improve the performance of a system in fact degrades after a certain point.
The biggest threats to improving the concurrency (or performance) of an application are Contention & Coherency delays. Let’s cover how to minimise them.
Contention
In an application, contention occurs when multiple processes or threads try to access a shared resource (CPU time, Memory, I/O such as disk or network, Locks in databases or in concurrent programming, common microservice, etc) at the same time. These are some of the strategies to tackle it.
Increase Resources (Parallelization)
Add more instances of the shared resource so that fewer processes are competing for the same resource. For example, add more CPUs or more memory or scale(horizontal or vertical).
The right amount of it makes sense if do this without thinking it will lead to Coherency delays which we will understand after some time.
Sharding or Partitioning
Divide data or tasks into smaller independent pieces that can be processed separately, reducing the need for shared access.
Queueing (Scheduling)
Implement a queue or scheduling system where tasks wait in line for access to the shared resource in an organized manner. This reduces the chaos of multiple processes fighting for access.
Caching
Reduce contention by caching frequently used data locally so that processes don’t need to access the shared resource as often.
This plays a lot of role if you want to know more about Caching then please read this article.
Reduce Lock Granularity
In systems where contention happens due to locking mechanisms (e.g., in databases or multi-threaded programming), use appropriate locking strategies based on the purpose like row-level locking in the database, Optimistic locking or compare-and-swap (CAS) over pessimistic locking where possible.
Coherency
coherency refers to ensuring that multiple copies of a shared resource (such as data) remain consistent across different processes, servers, or CPUs. This is especially critical in distributed systems, multi-threaded environments and systems with caches.
Due to Coherency Issues, we will face Race Conditions, Data Staleness, Increased Latency & Negative Scalability.
These are some of the strategies to tackle Coherency Issues.
Right Cache Strategy
Based on your need choose the right Cache strategy (Write-through or Write-back or etc)
Right Consensus Algorithm
In distributed systems (e.g., a distributed database like MongoDB or Cassandra), coherency is maintained through consensus algorithms(like Paxos or Raft) that ensure that all nodes agree on the state of the data.
Quorum-based Techniques
In distributed databases, a quorum-based approach ensures that a minimum number of nodes must agree on a transaction before it is considered successful. This helps in balancing performance and consistency.
Use quorum-based techniques where a subset of nodes must agree on transactions, improving consistency without requiring global consensus for every operation.
Eventual Consistency
If you are looking for higher availability & performance then you need to be ok with Eventual Consistency.
CAP Theorem: In distributed systems, it’s often difficult to achieve consistency, availability and partition tolerance simultaneously. Eventual consistency sacrifices strict consistency for higher availability and performance.
Did I miss anything? If yes, Please help me make it better by sharing your thoughts in the comments.
👋 Let’s be friends! Follow me on X and connect with me on LinkedIn. Don’t forget to Subscribe as well.
My X handle: https://x.com/ashok_tankala
My LinkedIn Profile: https://www.linkedin.com/in/ashoktankala/